


TÓM TẮT:
Bệnh tim mạch (Cardiovascular Disease - CVD) là nguyên nhân tử vong hàng đầu toàn cầu, đòi hỏi phương pháp chẩn đoán sớm và chính xác. Bài viết ứng dụng các mô hình học máy để dự đoán CVD dựa trên dữ liệu lâm sàng, với ba bộ dữ liệu chuẩn (UCI, Cleveland, Heart Dataset) và các thuật toán gồm Support Vector Machine, Logistic Regression, Random Forest, Gradient Boosting và K-Nearest Neighbors. Kết quả cho thấy mô hình ensemble, đặc biệt Random Forest, đạt độ chính xác trên 93% và ổn định hơn so với từng thuật toán đơn lẻ. Một ứng dụng web minh họa được xây dựng để chứng minh tính khả thi của mô hình trong thực tiễn, góp phần khẳng định tiềm năng của học máy trong chẩn đoán tim mạch.
Từ khóa: học máy, bệnh tim mạch, chẩn đoán y học, Ensemble Learning, GridSearchCV.
1. Đặt vấn đề
Bệnh tim mạch (Cardiovascular Disease - CVD) là nguyên nhân tử vong hàng đầu toàn cầu với gần 17,9 triệu ca mỗi năm (WHO, 2015). Chẩn đoán sớm và chính xác có vai trò quan trọng trong giảm biến chứng và nâng cao hiệu quả điều trị, trong khi các phương pháp truyền thống còn hạn chế về độ nhạy và khả năng phát hiện sớm. Trong bối cảnh đó, học máy (Machine Learning - ML) nổi lên như công cụ tiềm năng nhờ khả năng xử lý dữ liệu lớn, nhận diện mối quan hệ phi tuyến và đạt độ chính xác cao hơn thống kê cổ điển.
Bài viết tập trung triển khai và so sánh hiệu suất các mô hình tiêu biểu gồm SVM, Logistic Regression, Random Forest, Gradient Boosting và KNN, kết hợp tối ưu siêu tham số bằng GridSearchCV và thử nghiệm các kỹ thuật Ensemble Learning (stacking, voting, hybrid). Cách tiếp cận này kỳ vọng mang lại hệ thống chẩn đoán bệnh tim mạch chính xác, ổn định và có khả năng tổng quát hóa tốt, qua đó khẳng định vai trò của ML trong y học hiện đại và hỗ trợ bác sĩ lâm sàng.
2. Phương pháp nghiên cứu
Nghiên cứu tập trung vào dự đoán nguy cơ mắc bệnh tim mạch dựa trên các thông số lâm sàng như tuổi, giới tính, cholesterol, huyết áp, điện tâm đồ, đường huyết và nhịp tim gắng sức. Ba bộ dữ liệu chuẩn (UCI, Cleveland, Heart Dataset) được tổng hợp và chuẩn hóa để đảm bảo tính đa dạng và độ tin cậy. Năm thuật toán học máy tiêu biểu gồm Logistic Regression, SVM, Random Forest, Gradient Boosting, KNN được triển khai, kết hợp tiền xử lý dữ liệu, tối ưu siêu tham số bằng GridSearchCV và đánh giá bằng kiểm thử chéo k-fold. Ngoài các mô hình đơn lẻ, các kỹ thuật Ensemble Learning (voting, stacking, hybrid) cũng được áp dụng nhằm nâng cao hiệu suất và khả năng tổng quát hóa.
2.1. Bộ dữ liệu
Trong nghiên cứu này, chất lượng và đặc trưng của dữ liệu được coi là yếu tố then chốt, quyết định hiệu quả của mô hình học máy. Ba bộ dữ liệu chuẩn về bệnh tim được lựa chọn, sau khi chuẩn hóa các biến và quy đổi nhãn mục tiêu từ 5 mức (0-4) về hai lớp “có bệnh” và “không bệnh”. Dữ liệu sau chuẩn hóa và gộp thành tập tích hợp khoảng 1.800 mẫu với 14 thuộc tính, đảm bảo tính đa dạng và khả năng so sánh kết quả. Tiếp đó, dữ liệu được phân tích phân bố, xử lý giá trị thiếu và chuẩn hóa thành dạng vector số để đưa vào huấn luyện mô hình.
Bộ dữ liệu UCI Heart Disease gồm 920 mẫu với 15 biến đầu vào về nhân khẩu học, lâm sàng và cận lâm sàng (tuổi, giới tính, huyết áp, cholesterol, điện tâm đồ, nhịp tim gắng sức, đau thắt ngực, số mạch vành, thalassemia…) và 1 biến đầu ra (num). Biến mục tiêu phản ánh chẩn đoán bệnh tim theo 5 mức, từ 0 (không bệnh) đến 4 (nặng).
Bộ dữ liệu Cleveland Heart Disease gồm 303 mẫu với 14 biến đặc trưng về nhân khẩu học, sinh hóa, điện tâm đồ và thông số gắng sức, được sử dụng rộng rãi trong nghiên cứu học máy y sinh. Biến mục tiêu (num) phản ánh tình trạng bệnh tim theo hai lớp (có/không bệnh) hoặc phân mức từ 1 đến 4. Mặc dù còn hạn chế về kích thước mẫu nhỏ và giá trị khuyết ở một số biến (ca, thal), tập dữ liệu này vẫn có giá trị học thuật cao và thường được xem là chuẩn mực để đánh giá mô hình.
Bộ dữ liệu Heart được tổng hợp và chuẩn hóa từ Cleveland, Hungarian cùng các nguồn mở (Kaggle, UCI) nhằm tăng quy mô và đa dạng bệnh nhân, cải thiện độ tin cậy và khả năng khái quát hóa. Tập cuối gồm 1.025 mẫu, 13 biến đặc trưng lâm sàng-cận lâm sàng và 1 biến mục tiêu (target). Dữ liệu còn tồn tại giá trị thiếu, ngoại lai và mất cân bằng lớp nên cần tiền xử lý chặt chẽ.
2.2. Xử lý dữ liệu
Trong nghiên cứu, nhóm khai thác 5 bộ dữ liệu tim mạch nhằm tăng tính đa dạng và độ tin cậy, gồm 3 bộ gốc (UCI Heart Disease, Cleveland Heart Disease, Heart) và 2 bộ mở rộng:
- Merged Dataset (~1.800 mẫu, 14 thuộc tính): chuẩn hóa biến (ví dụ biến target từ 5 nhãn về 2 nhãn có/không bệnh) và gộp dữ liệu từ nhiều nguồn, được sử dụng chính trong huấn luyện.
- Combined Dataset (~1.200 mẫu): được tạo qua công cụ xử lý riêng, với các đặc trưng đã tinh chỉnh và đồng bộ.
+ Các bước tiền xử lý gồm kiểm tra dữ liệu, xử lý giá trị khuyết, chuẩn hóa biến liên tục (huyết áp, cholesterol, nhịp tim…) và mã hóa biến phân loại (giới tính, loại đau ngực, thalassemia). Sau chuẩn hóa, dữ liệu được chia 80% huấn luyện - 20% kiểm tra, đảm bảo đánh giá khách quan và nâng cao khả năng khái quát hóa khi áp dụng thực tiễn.
+ Các cặp đặc trưng tập dữ liệu Heart có tương quan cao (|r| > 0.5), oldpeak ↔ target: 0.735.
+ Các cặp đặc trưng tập dữ liệu Cleveland Heart Disease có tương quan cao (|r| > 0.5), oldpeak ↔ slope: 0.527, thal ↔ target: 0.525. Không có cặp đặc trưng nào của tập dữ liệu UCI Heart Disease có tương quan cao (|r| > 0.5).
+ Các cặp đặc trưng tập dữ liệu Merge có tương quan cao (|r| > 0.5), oldpeak ↔ target: 0.593.
Các bước tiền xử lý này không chỉ giúp mô hình học máy khai thác thông tin hiệu quả hơn, mà còn góp phần hạn chế overfitting và nâng cao khả năng tổng quát hóa khi áp dụng vào thực tế.
2.3. Thuật toán học máy
2.3.1. Thuật toán Support Vector Machine
SVM là thuật toán học máy có giám sát, thường dùng cho phân loại nhị phân và có thể mở rộng sang đa lớp hoặc hồi quy. Thuật toán tìm siêu phẳng tối ưu với khoảng cách biên lớn nhất, xử lý tốt dữ liệu phi tuyến nhờ kernel trick, với các hàm nhân phổ biến như tuyến tính, polynomial và Gaussian RBF (Vapnik, 1995; Schölkopf & Smola, 2002).
Trong chẩn đoán bệnh tim, SVM cho thấy hiệu quả cao trong phân loại dữ liệu lâm sàng đa chiều, thường được so sánh với Random Forest, KNN, Decision Tree và Logistic Regression. Hiệu suất có thể cải thiện nhờ mô hình lai, tối ưu siêu tham số và chọn đặc trưng.
2.3.2. Thuật toán Logistic Regression
Logistic Regression (LR) là mô hình thống kê có giám sát, thường dùng cho phân loại nhị phân bằng cách ánh xạ xác suất về [0,1] qua hàm sigmoid (Bewick, Cheek & Ball, 2005). Ưu điểm nổi bật là khả năng diễn giải thông qua odds ratio, nên được ứng dụng rộng rãi trong y học và dịch tễ học (Schober & Vetter, 2021).
Linear Regression có thể cho ra giá trị dự đoán ngoài khoảng xác suất, trong khi Logistic Regression (LR) sử dụng đường cong sigmoid để giới hạn kết quả trong [0,1], đảm bảo ý nghĩa thống kê và dễ diễn giải trong y học.
2.3.3. Thuật toán Random Forest
Random Forest (RF) là một phương pháp học máy dựa trên tập hợp nhiều cây quyết định (decision trees) nhằm nâng cao hiệu quả phân loại và giảm hiện tượng overfitting. Thuật toán hoạt động bằng cách xây dựng nhiều cây trên các mẫu dữ liệu ngẫu nhiên và đưa ra dự đoán cuối cùng dựa trên cơ chế bỏ phiếu đa số (majority voting) (Lamir, Razzagzadeh & Rezaei, 2025). Nhờ cấu trúc ensemble, RF có khả năng xử lý dữ liệu lớn, nhiều biến và ít nhạy cảm với nhiễu hơn so với các mô hình đơn lẻ.
2.3.4. Thuật toán Gradient Boosting
Gradient Boosting (GB) là phương pháp boosting xây dựng dần một tập các cây yếu, trong đó mỗi cây mới sửa lỗi của mô hình trước đó. Thuật toán thường đạt độ chính xác cao và xử lý hiệu quả dữ liệu phi tuyến.
Trong dự đoán bệnh tim, GB được đánh giá cao nhờ hiệu suất vượt trội, đặc biệt khi kết hợp với kỹ thuật tối ưu siêu tham số (Friedman, 2001).
2.3.5. Thuật toán K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) là thuật toán phân loại dựa trên khoảng cách, gán nhãn cho mẫu mới theo đa số của k điểm lân cận gần nhất. Mô hình đơn giản nhưng hiệu quả, đặc biệt với dữ liệu nhỏ và phân bố đều.
Trong y học, KNN thường được dùng để chẩn đoán bệnh tim và đã chứng minh hiệu quả với độ chính xác cạnh tranh so với các mô hình phức tạp hơn (Shouman, Turner & Stocker, 2012).
2.3.6. Thuật toán Decision Tree
Decision Tree (DT) là mô hình phân loại dạng cây, phân tách dữ liệu tuần tự theo đặc trưng để đưa ra quyết định cuối cùng. Mô hình dễ hiểu và trực quan, phù hợp với y học, nhưng dễ overfitting nên thường dùng trong các ensemble như RF hay Gradient Boosting (Podgorelec et. al., 2002).
Nhiều nghiên cứu cho thấy Decision Tree (DT) đạt hiệu quả cao: trong chẩn đoán bệnh thận mạn, mô hình đạt độ chính xác 98,6% với độ nhạy 97,2% và độ đặc hiệu 100% (Sharma et. al., 2016); trong dự đoán bệnh tim mạch, DT thậm chí đạt độ chính xác tới 99%, vượt cả Random Forest trong một số trường hợp (Zriqat, Altamimi & Azzeh, 2017).
2.3.7. Kỹ thuật tinh chỉnh siêu tham số với GridSearchCV
Trong xây dựng mô hình học máy, ngoài việc chọn thuật toán, tinh chỉnh siêu tham số giữ vai trò quyết định trong nâng cao độ chính xác và khả năng khái quát hóa. Ví dụ: số cây trong Random Forest, k trong KNN hay learning rate trong Gradient Boosting. GridSearchCV thực hiện tìm kiếm toàn diện bằng cách tạo lưới giá trị siêu tham số, đánh giá từng tổ hợp qua k-fold cross-validation và chọn cấu hình có hiệu suất trung bình cao nhất.
GridSearchCV là phương pháp tìm kiếm toàn diện trên lưới tham số định sẵn, kết hợp cross-validation để đánh giá và chọn cấu hình tối ưu (Pedregosa et al., 2011). So với Random Search, vốn thử ngẫu nhiên và phù hợp khi không gian tham số quá lớn, GridSearchCV ưu tiên tính toàn diện và độ tin cậy, nên đặc biệt phù hợp cho các ứng dụng y học đòi hỏi độ chính xác cao.
2.3.8. Ensemble Learning tối ưu mô hình
Ensemble Learning kết hợp nhiều mô hình để tăng độ chính xác, tính ổn định và khả năng tổng quát hóa (Zhou, 2025). Sau khi tối ưu siêu tham số bằng GridSearchCV hoặc Random Search, các mô hình được ghép theo nguyên tắc “wisdom of the crowd” nhằm giảm overfitting và nhiễu, tạo dự đoán tổng hợp H(x)H(x)H(x) từ các mô hình con (Dietterich, 2000):
h1(x),…,hM(x)h_1(x), …, h_M(x)h1(x),…,hM(x)
(1) Bài toán hồi quy (Regression):
![]()
Mô hình tổng hợp là giá trị trung bình của các dự đoán.
(2) Bài toán phân loại (Classification):
- Voting (bỏ phiếu đa số):
![]()
Trong đó, 1 là hàm chỉ báo, bằng 1 nếu mô hình hm (x) dự đoán nhãn y, ngược lại là 0.
- Weighted Voting (bỏ phiếu có trọng số):
![]()
Trong đó, wm là trọng số phản ánh độ tin cậy của mô hình hm.
Các mô hình sau khi tối ưu siêu tham số được kết hợp theo ba chiến lược: Voting (bỏ phiếu đa số giữa LR, SVM, RF để tăng ổn định), Stacking (dùng meta-learner như Logistic Regression để kết hợp kết quả tối ưu) và Boosting (Gradient Boosting, huấn luyện tuần tự nhiều mô hình yếu để cải thiện chính xác). Kết quả cho thấy, Ensemble nâng cao đáng kể hiệu suất so với mô hình đơn lẻ, đồng thời giảm overfitting và tăng khả năng dự đoán bệnh tim.
3. Triển khai và đánh giá các mô hình học máy
Giai đoạn tiếp theo là lựa chọn, huấn luyện và đánh giá mô hình, nhằm xác định thuật toán dự đoán bệnh tim hiệu quả nhất. Theo định hướng Hands-On Machine Learning, thay vì chọn ngay một mô hình, nhiều thuật toán được thử nghiệm để thiết lập baseline performance, từ đó chọn mô hình tối ưu để tinh chỉnh sâu hơn.
3.1. Triển khai kỹ thuật đánh giá chéo
Để ước lượng đáng tin cậy hơn về hiệu suất, nghiên cứu sử dụng K-Fold Cross Validation thay vì chia train–test một lần. Với 𝐾 =10, dữ liệu được chia thành 10 phần, mỗi lần 9 phần huấn luyện và 1 phần kiểm tra, kết quả lấy trung bình và độ lệch chuẩn. Phương pháp này giảm ảnh hưởng ngẫu nhiên, phát hiện overfitting và giữ cân bằng nhãn nhờ StratifiedKFold. Các chỉ số đánh giá gồm Accuracy, Precision, Recall, F1-score và ROC-AUC, đảm bảo so sánh toàn diện giữa các mô hình.
3.2. Huấn luyện các mô hình cơ sở
Trong nghiên cứu, một tập hợp các mô hình phân loại phổ biến từ Scikit-Learn được lựa chọn để huấn luyện ban đầu, nhằm khai thác cả quan hệ tuyến tính và phi tuyến tính trong dữ liệu. Các mô hình cơ sở bao gồm:
(1) Logistic Regression một mô hình tuyến tính đơn giản nhưng hiệu quả, có khả năng diễn giải cao và thường được dùng làm điểm khởi đầu để đánh giá độ phức tạp của bài toán.
Hình 1: Đường cong học (Learning Curve) mô hình Logistic Regression
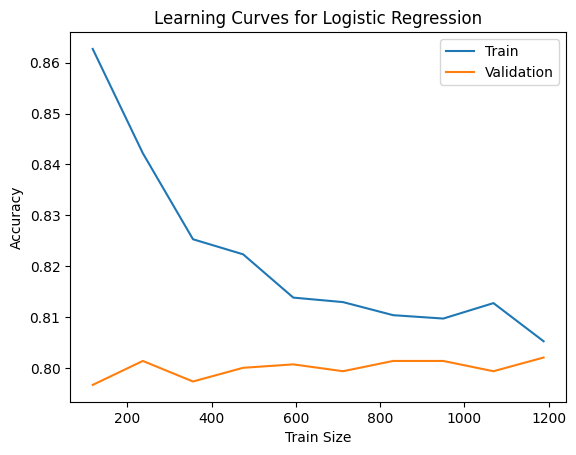
Đường cong học Logistic Regression cho thấy độ chính xác huấn luyện giảm dần và hội tụ với độ chính xác kiểm định quanh mức ~0.80. Khoảng cách nhỏ giữa hai đường chứng tỏ không overfitting, nhưng mức chính xác trung bình phản ánh hiện tượng underfitting nhẹ.
(2) K-Nearest Neighbors (KNN) là thuật toán phi tham số, phân loại dựa trên “phiếu bầu” của k láng giềng gần nhất. Hiệu suất phụ thuộc vào lựa chọn k và thước đo khoảng cách.
Hình 2: Đường cong học (Learning Curve) mô hình K-Nearest Neighbors
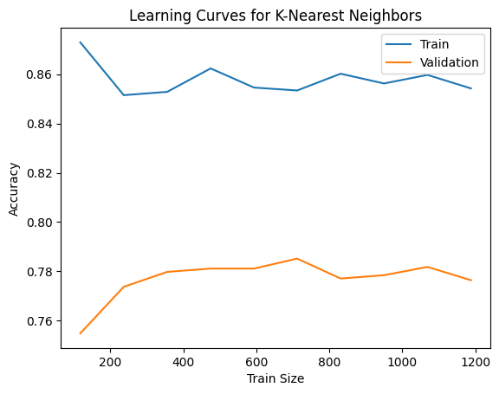
Đường cong học của KNN cho thấy huấn luyện đạt ~0.85-0.87, trong khi kiểm định chỉ ~0.76-0.78, phản ánh overfitting rõ rệt. Có thể cải thiện bằng cách tinh chỉnh k hoặc giảm chiều dữ liệu để tăng khả năng tổng quát hóa.
(3) Support Vector Machine (SVM) phân loại bằng cách tìm siêu phẳng tối ưu trong không gian nhiều chiều và có thể xử lý quan hệ phi tuyến nhờ kernel (ví dụ: RBF).
Hình 3: Đường cong học (Learning Curve) mô hình Support Vector Machine
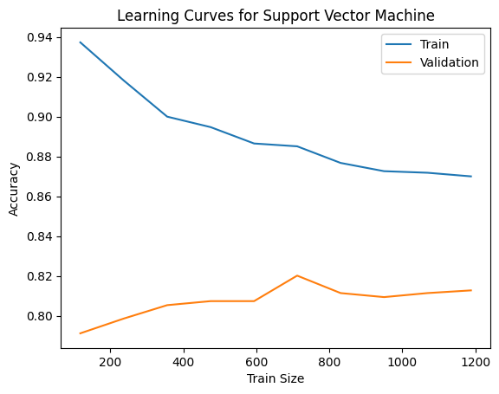
Đường cong học của SVM cho thấy huấn luyện giảm từ ~0.94 xuống ~0.87, còn kiểm định ổn định quanh ~0.81-0.82. Khoảng cách lớn phản ánh overfitting, nhưng có thể cải thiện bằng mở rộng dữ liệu hoặc tinh chỉnh siêu tham số (C, gamma, kernel).
(4) Decision Tree (DT) là mô hình phi tuyến tính mô phỏng quá trình ra quyết định bằng cấu trúc cây gồm các nút và nhánh, với tiêu chí phân tách như Gini Impurity hoặc Entropy.
Hình 4: Đường cong học (Learning Curve) mô hình Decision Tree
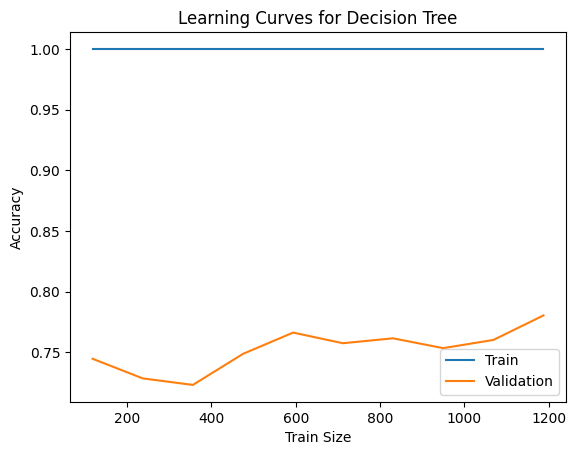
Đường cong học của Decision Tree (DT) cho thấy huấn luyện đạt 1.0 nhưng kiểm định chỉ ~0.72-0.78, phản ánh overfitting nghiêm trọng; có thể khắc phục bằng giới hạn độ sâu, giảm số nút lá hoặc dùng mô hình tổ hợp như Random Forest hay Gradient Boosting.
3.3. Huấn luyện mô hình theo phương pháp Ensemble Learning
Ensemble Learning là kỹ thuật kết hợp nhiều mô hình học máy nhằm cải thiện độ chính xác và khả năng tổng quát hóa. Trong nghiên cứu này, hai phương pháp ensemble được áp dụng: Random Forest và Gradient Boosting.
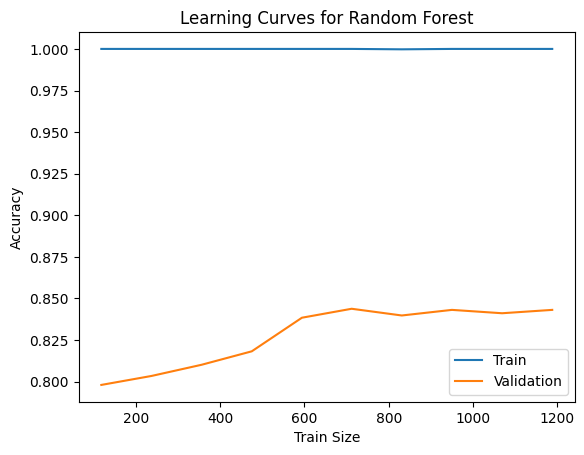
(1) Random Forest (RF) dựa trên cơ chế bagging, xây dựng nhiều cây quyết định từ mẫu bootstrap và tập đặc trưng ngẫu nhiên, sau đó tổng hợp dự đoán bằng bỏ phiếu đa số. Mô hình đạt độ chính xác huấn luyện gần tuyệt đối, trong khi kiểm định khoảng 0.80–0.84, cho thấy hiệu suất cao nhưng có dấu hiệu overfitting; việc điều chỉnh số cây, độ sâu và số đặc trưng có thể cải thiện kết quả.
Hình 5: Đường cong học (Learning Curve) mô hình Random Forest
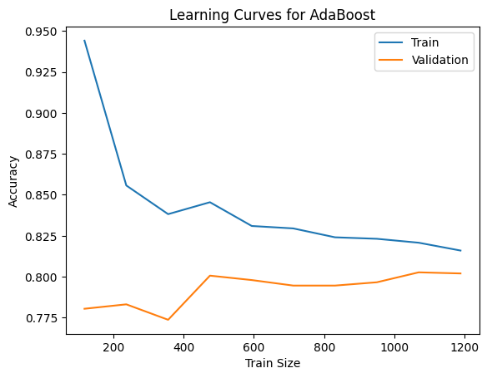
(2) Gradient Boosting (GB/XGBoost) xây dựng cây tuần tự, mỗi cây sửa lỗi cây trước, nổi bật nhờ hiệu suất và tốc độ. Đường cong học cho thấy huấn luyện giảm từ ~0.94 xuống ~0.82, kiểm định ổn định 0.78-0.80, phản ánh overfitting giảm nhưng hiệu suất còn trung bình.
Hình 6: Đường cong học (Learning Curve) mô hình Gradient Boosting
3.4. So sánh hiệu suất các mô hình
Sau khi huấn luyện tất cả các mô hình cơ sở và các mô hình ensemble bằng quy trình đánh giá chéo 10 lần trên tập huấn luyện, hiệu suất của chúng được tổng hợp và so sánh trong Bảng 1. Các độ đo được báo cáo là giá trị trung bình thu được từ 10 lần gấp.
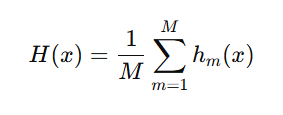 Bảng 1. Kết quả cross-validation của các mô hình trên tập huấn luyện
Bảng 1. Kết quả cross-validation của các mô hình trên tập huấn luyện
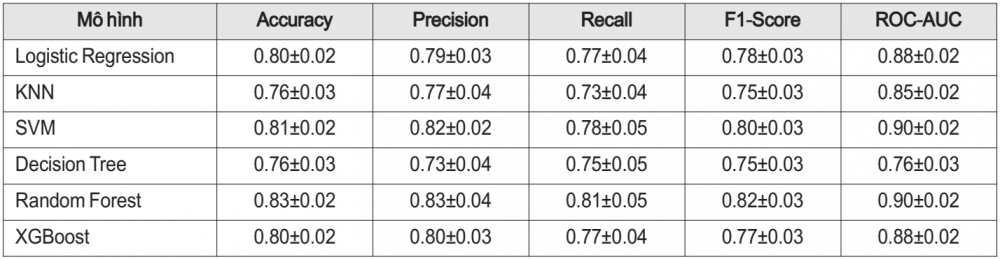
Kết quả cho thấy, Random Forest đạt hiệu suất toàn diện nhất (Accuracy 0.83, F1-Score 0.82, ROC-AUC 0.90), cân bằng tốt giữa Precision và Recall (0.81), phù hợp bối cảnh y tế. SVM xếp thứ hai với ROC-AUC tương đương (0.90), thể hiện khả năng phân biệt rõ ràng giữa bệnh nhân có và không bệnh. Logistic Regression và XGBoost cho kết quả ổn định (Accuracy 0.80, ROC-AUC 0.88) nhưng kém hơn hai mô hình dẫn đầu. Trong khi đó, Decision Tree dễ overfitting nên cho hiệu suất thấp nhất, còn KNN chỉ đạt mức trung bình. Tổng thể, Random Forest nổi bật nhờ hiệu suất vượt trội, độ tin cậy cao và khả năng xác định tầm quan trọng của đặc trưng, được xem là mô hình triển vọng nhất cho chẩn đoán bệnh tim.
4. Tinh chỉnh và phân tích mô hình
Sau khi xác định Random Forest là mô hình hiệu quả nhất, nhóm tiếp tục tinh chỉnh siêu tham số và phân tích khả năng diễn giải để tăng hiệu suất và độ tin cậy. Các tham số chính như n_estimators, max_depth và min_samples_split được tối ưu bằng GridSearchCV kết hợp cross-validation.
Bảng 2. So sánh hiệu suất mô hình Random Forest trước và sau khi tinh chỉnh
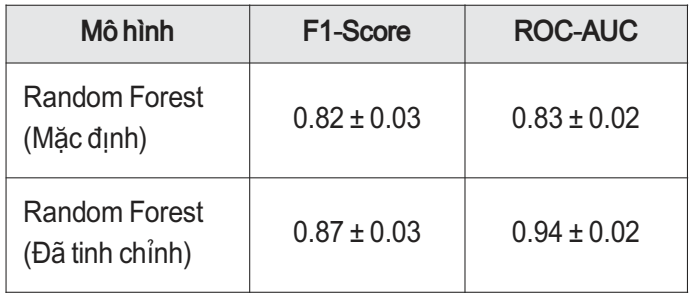
Kết quả cho thấy mô hình sau tinh chỉnh cải thiện rõ rệt về F1-Score và ROC-AUC, đồng thời giảm sai lệch.
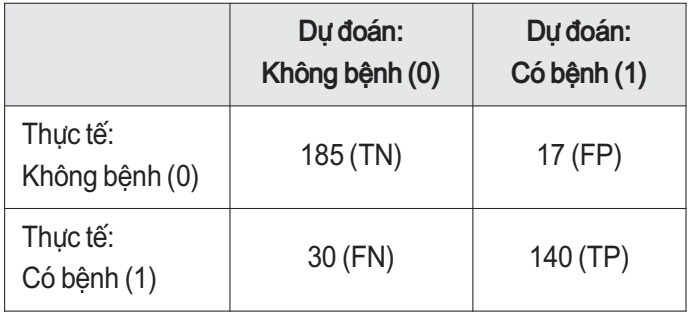
Mô hình Random Forest tối ưu được kiểm tra trên test set cho thấy Accuracy 88.4%, F1-Score 87.0%, ROC-AUC 94.6%, duy trì cân bằng giữa Precision và Recall.
Ma trận nhầm lẫn minh họa khả năng phân loại tốt, với số FN thấp, phù hợp ưu tiên trong y tế.
Bảng 3. Ma trận nhầm lẫn trên tập kiểm tra
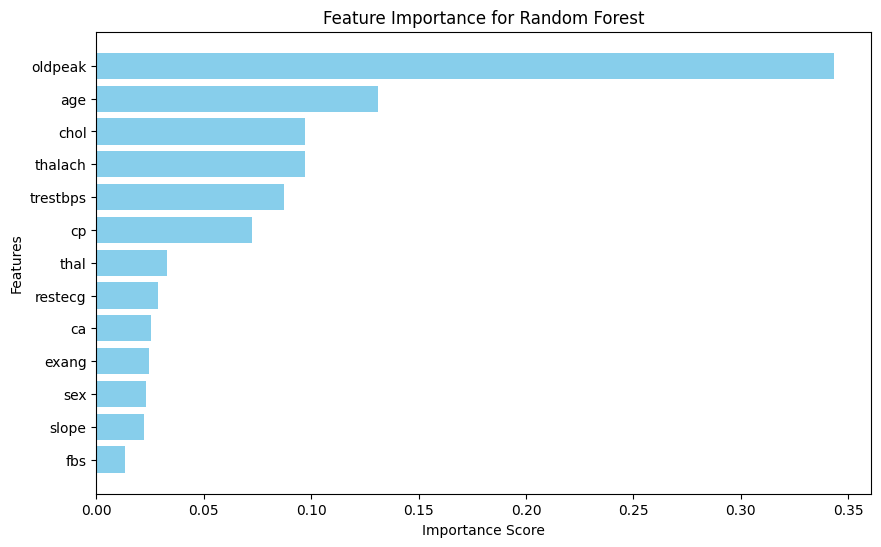
Phân tích Feature Importance cho thấy oldpeak là đặc trưng quan trọng nhất, theo sau là age, chol, thalach và trestbps.
Ở mức độ cá nhân, kỹ thuật SHAP cho phép giải thích minh bạch các dự đoán, hỗ trợ bác sĩ đối chiếu với kiến thức lâm sàng.
Hình 7: Biểu đồ của các đặc trưng quan trọng trong mô hình Random Forest cho bài toán dự đoán bệnh tim
Nhóm sử dụng SHAP để phân tích mức đóng góp của từng đặc trưng, giúp mô hình minh bạch hơn trong ứng dụng lâm sàng. SHAP Force Plot cho thấy cách các yếu tố rủi ro đẩy hoặc kéo xác suất dự đoán của một bệnh nhân cụ thể.
Hình 8: Biểu đồ SHAP Force Plot

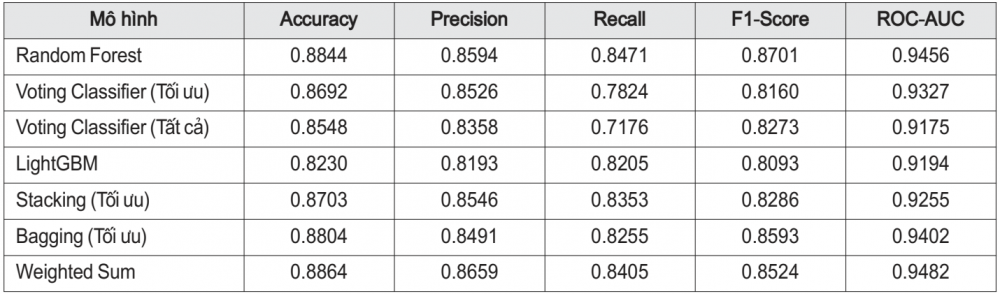
Nhóm áp dụng Voting Classifier kết hợp Random Forest, SVM và Logistic Regression. Kết quả cho thấy, ensemble không vượt qua Random Forest tối ưu, do ảnh hưởng từ mô hình yếu hơn và sự trùng lặp lỗi.
Voting Classifier cho kết quả khá nhưng vẫn kém Random Forest tối ưu, do ảnh hưởng từ mô hình yếu và trùng lặp lỗi. Trong y tế, Random Forest với độ chính xác, ổn định và minh bạch cao là lựa chọn phù hợp để hỗ trợ chẩn đoán bệnh tim.
Bảng 4. So sánh các phương pháp trong việc áp dụng mô hình EVC
5. Đánh giá và kết luận
5.1. Đánh giá kết quả
Nghiên cứu đã xây dựng quy trình học máy toàn diện cho dự đoán bệnh tim mạch, với dữ liệu UCI Heart Disease được tiền xử lý bằng Pipeline Scikit-Learn để đảm bảo tính nhất quán và hạn chế rò rỉ. Qua so sánh, Random Forest được xác định là mô hình hiệu quả nhất; sau khi tinh chỉnh bằng GridSearchCV, đạt F1-Score 87.0%, ROC-AUC 94.6%, cân bằng tốt giữa Precision (89.4%) và Recall (84.7%). Phân tích đặc trưng cho thấy, oldpeak, cp, thal là yếu tố dự báo quan trọng, trong khi SHAP tăng cường khả năng diễn giải, giúp mô hình trở thành công cụ minh bạch và hữu ích trong hỗ trợ lâm sàng.
5.2. Đánh giá kết quả
Nghiên cứu khẳng định tính khả thi và giá trị thực tiễn của việc ứng dụng học máy trong dự đoán bệnh tim, đặc biệt khi mô hình được lựa chọn, tinh chỉnh và diễn giải theo quy trình khoa học. Kết quả cho thấy, mô hình không chỉ đạt hiệu suất cao mà còn đảm bảo tính minh bạch và độ tin cậy trong bối cảnh lâm sàng.
Tuy nhiên, nghiên cứu vẫn còn hạn chế về quy mô và tính đa dạng dữ liệu. Hướng phát triển tiếp theo là mở rộng tập dữ liệu, bổ sung thêm yếu tố phi lâm sàng và kiểm nghiệm trên nhiều nhóm bệnh nhân, nhằm nâng cao khả năng khái quát và ứng dụng trong thực tế y tế.
TÀI LIỆU THAM KHẢO:
Bewick, V., Cheek, L., & Ball, J. (2005). Statistics review 14: Logistic regression. Critical care, 9(1), 112.
Dietterich, T. G. (2000). Ensemble methods in machine learning. International workshop on multiple classifier system. [Online] Available at https://web.engr.oregonstate.edu/~tgd/publications/mcs-ensembles.pdf
Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, 1189-1232.
Lamir, A. A., Razzagzadeh, S., & Rezaei, Z. (2025). A Comprehensive Machine Learning Framework for Heart Disease Prediction: Performance Evaluation and Future Perspectives. arXiv preprint arXiv:2505.09969.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., & Dubourg, V. (2011). Scikit-learn: Machine learning in Python. the Journal of machine Learning research, 12, 2825-2830.
Podgorelec, V., Kokol, P., Stiglic, B., & Rozman, I. (2002). Decision trees: an overview and their use in medicine. Journal of medical systems, 26(5), 445-463.
Sharma, S., Sharma, V., & Sharma, A. (2016). Performance based evaluation of various machine learning classification techniques for chronic kidney disease diagnosis. arXiv preprint arXiv:1606.09581.
Schober, P., & Vetter, T. R. (2021). Logistic regression in medical research. Anesthesia & Analgesia, 132(2), 365-366.
Schölkopf, B., & Smola, A. J. (2002). Learning with kernels: support vector machines, regularization, optimization, and beyond. USA: MIT press.
Shouman, M., Turner, T., & Stocker, R. (2012). Applying k-nearest neighbour in diagnosing heart disease patients. International Journal of Information and Education Technology, 2(3), 220-223.
Vapnik, V. (1995). Support-vector networks. Machine learning, 20, 273-297.
World Health Organization - WHO (2015). Cardiovascular diseases (CVDs). [Online] Available at https://www.who.int/vietnam/vi/health-topics/cardiovascular-disease
Zhou, Z.-H. (2025). Ensemble methods: foundations and algorithms. Chinese: CRC press.
Zriqat, I. A., Altamimi, A. M., & Azzeh, M. (2017). A comparative study for predicting heart diseases using data mining classification methods. arXiv preprint arXiv:1704.02799.
APPLICATION OF MACHINE LEARNING MODELS
FOR CARDIOVASCULAR DISEASE DIAGNOSIS USING CLINICAL DATA
TRAN THI MINH ANH1,2
PHAM THI MIEN2
1Ho Chi Minh City University of Technical Education
2University of Transport and Communication - Ho Chi Minh City Campus
ABSTRACT:
Cardiovascular disease (CVD) remains the leading cause of mortality worldwide, underscoring the need for early and accurate diagnosis. This study applies machine learning techniques to predict CVD based on clinical datasets, including the UCI, Cleveland, and Heart datasets. Five algorithms, including: Support Vector Machine, Logistic Regression, Random Forest, Gradient Boosting, and K-Nearest Neighbors, were evaluated and compared. The results indicate that ensemble models, particularly Random Forest, achieved the highest performance with an accuracy exceeding 93%, demonstrating superior stability and predictive capability over individual models. Furthermore, a prototype web application was developed to illustrate the model’s practical applicability, highlighting the potential of machine learning as an effective tool to support cardiovascular disease diagnosis and early intervention.
Keywords: machine learning, cardiovascular disease, medical diagnosis, Ensemble Learning, GridSearchCV.
[Tạp chí Công Thương - Các kết quả nghiên cứu và ứng dụng công nghệ số 27 tháng 9 năm 2025]







